

Products and services


Speed matters. Have you ever felt frustrated because an AI system was too slow to respond? If the waiting time were cut in half, the experience would feel much less stressful. Quality matters too. Have you ever felt frustrated because an AI system gave you a wrong answer? If an AI system made only half as many mistakes, your work would become much smoother. But can we really have both speed and quality? Intuitively, it seems that if we rush the output, the quality should suffer. In Accelerating Deep Neural Networks, I explain how AI systems can be made both faster and more accurate, and why this is possible.
The intuition is simple: when our thoughts are well organized, we can answer more quickly, and our answers are often better. A well organized neural network can also be processed efficiently, if we know how to take advantage of that structure. By contrast, a poor-quality neural network is messy and disorganized, and therefore difficult to compute efficiently. In other words, if we can find a way to obtain well organized neural networks, we may get a very convenient result: systems that are both fast and accurate.
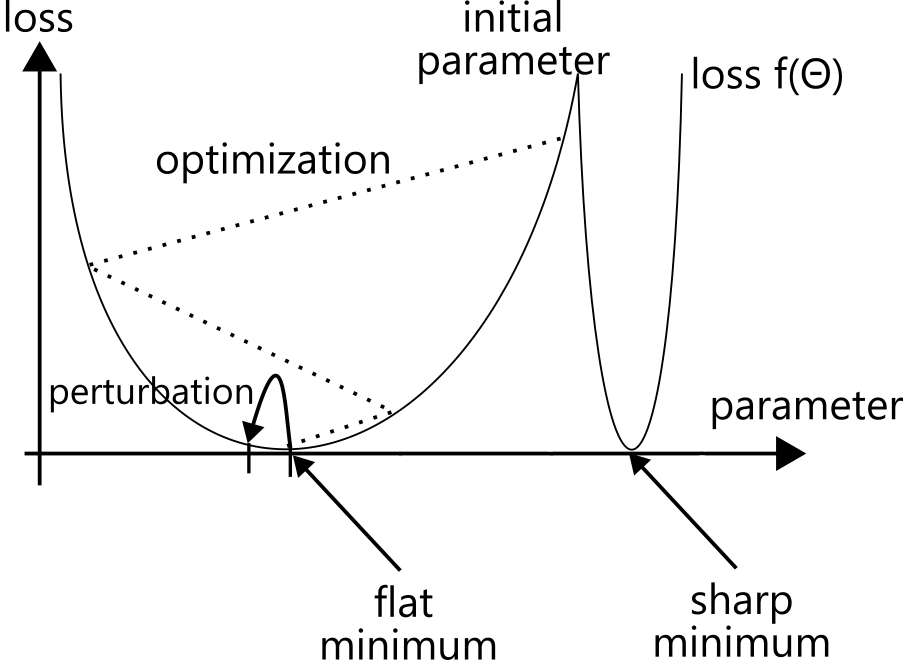
The mathematical concept behind this intuition is that of a flat minimum. A flat minimum is a setting of the parameters where the quality of the model does not change much even if the parameters are perturbed slightly. This corresponds to an organized state. A sharp minimum, on the other hand, is a parameter setting where even a small change can cause a large drop in quality. This corresponds to a messy and disorganized state. Very roughly speaking, it is like memorizing a textbook word for word before an exam. The knowledge is fragile: even a small distraction can make it collapse. A flat minimum is more like genuine understanding. It is stable, and it does not fall apart because of a small disturbance. In this sense, a model at a flat minimum makes fewer mistakes.
What is more, a flat minimum is easier to compute quickly. If slightly changing the values does not affect quality, perhaps we do not need to compute everything in full 32-bit precision. Perhaps 8-bit computation is enough. Perhaps we can even skip some computations, and the model will still reach the correct answer. Surprisingly, this intuition is correct. In practice, models at flat minima tend to preserve their quality even when we compute them more aggressively and efficiently.
Accelerating Deep Neural Networks introduces a wide range of techniques for speeding up neural networks and large language models. Many of these methods are practical tools already used in real systems. But behind them lies the same principle described above: the connection between organized structure and efficient computation. The book explains not only how neural networks can be accelerated, but also why such acceleration is possible. I hope it will be useful not only to readers who want to make neural networks faster, but also to those who want to understand the deeper reason why speedups are possible at all.


Ryoma Sato is Assistant Professor at the National Institute of Informatics, Japan, specializing in graph neural networks, optimal transport, and efficient deep learning. He is the ...
View profile >Keep up with the latest from Cambridge University Press on our social media accounts.







Latest Comments
Have your say!